Always present your dollar figures in a magnitude that will be intuitive for your audience. During analysis you’ll be aggregating and disaggregating numbers frequently. Here’s a simple tip for changing magnitudes.
\(10^0\) = 1 = one
\(10^3\) = 1,000 = one thousand
\(10^6\) = 1,000,000 = one million
\(10^9\) = 1,000,000,000 = one billion
\(10^{12}\) = 1,000,000,000,000 = one trillion
Larger magnitude to smaller magnitude: If you are going from a number in trillions (\(10^{12}\) ), such as a large country’s GDP, to a number in the thousands (\(10^3\) ), such as that country’s per capita GDP, take the following steps:
subtract the exponents: 12 - 3 = 9. Then multiply by 10 to that exponent (9).
$0.000000027 trillion * \(10^9\) = $27 thousand
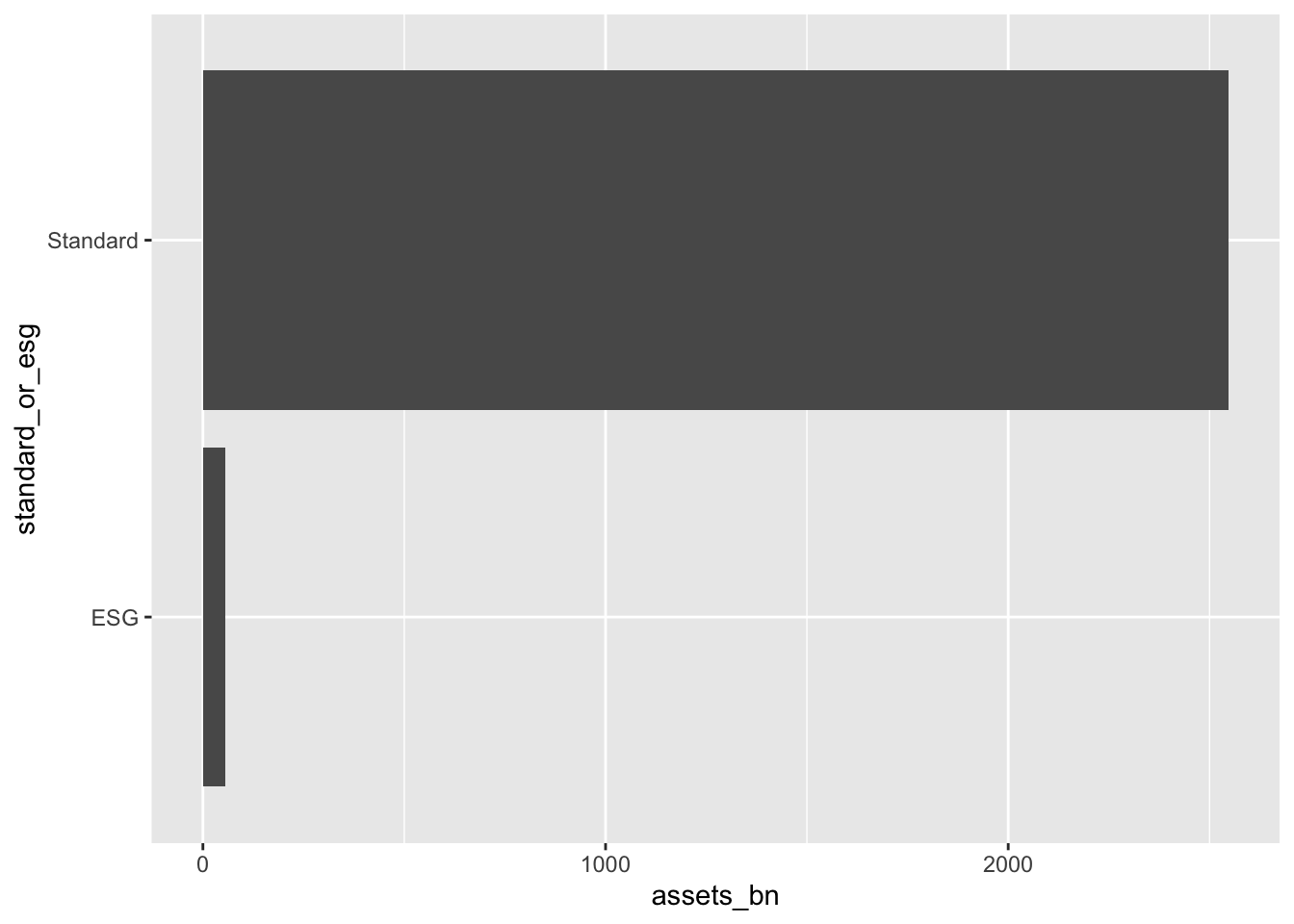
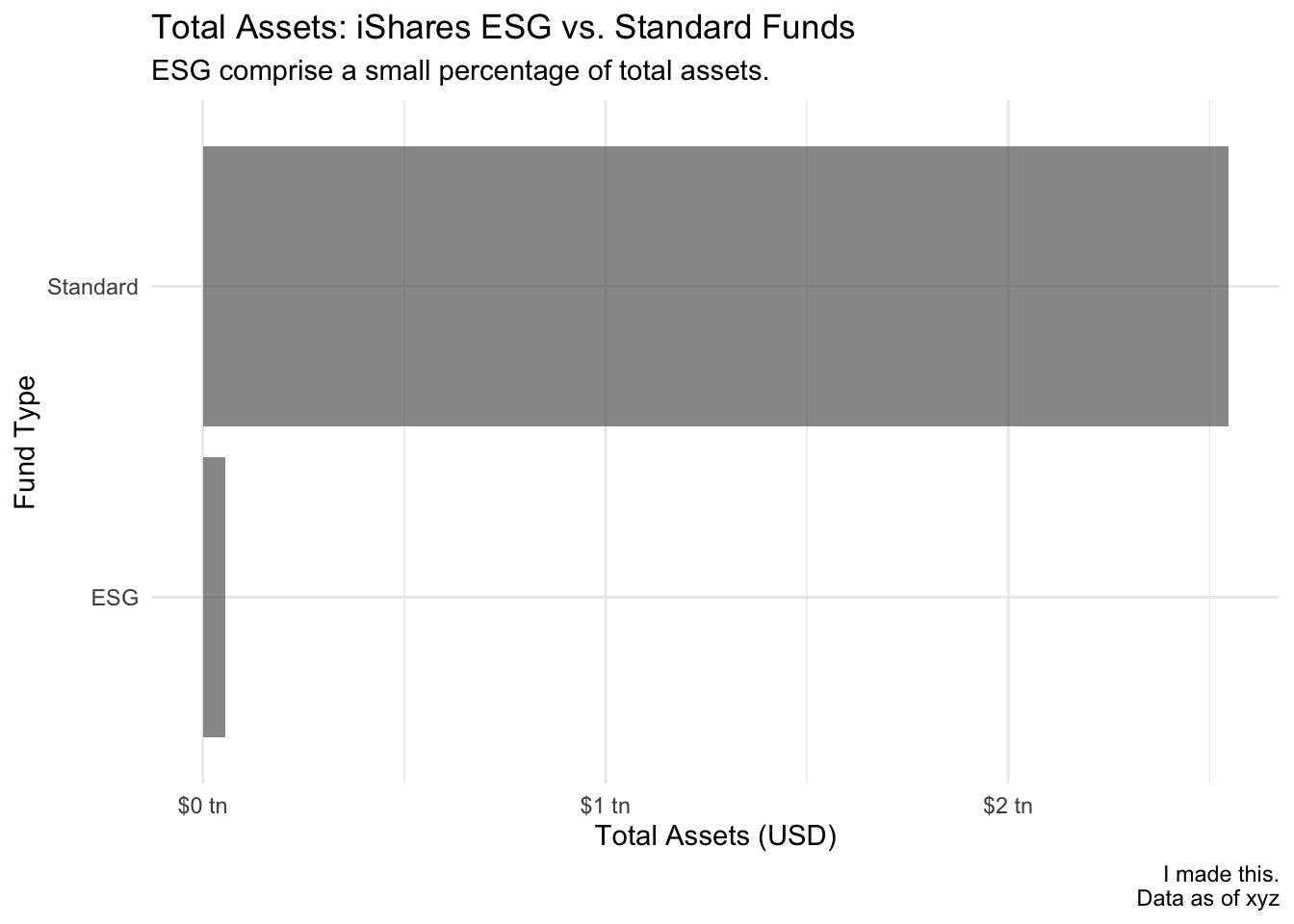
Smaller magnitude to larger magnitude: We saw this above. Assets in standard ETFs were $2,547,421,888,526 . This is expressed in units of 1 (\(10^0\)), when it really makes sense to express it in trillions (\(10^{12}\)).
subtract the expontents: 0-12 = -12. Then multpily by 10 to that exponent (-12). Multiplying by a negative exponent is the same as dividing, so do it whichever way you prefer.
$2,547,421,888,526 * \(10^{-12}\) = $2.5 trillion